3.5.1. ARM 架构概述
- MCU、MPU、SoC
(1)MCU(微控制器):集成 CPU、SRAM、FLASH、诸多外设;低功耗、低成本、体积小,无依赖
(2)MPU(微处理器):只有强大的 CPU 和 MMU,其他几乎没有;高功耗、高性能、强依赖
(3)SoC(片上系统):范围很广,既包括 MCU 也包括 MPU 还包括其他,MCU 属于低端 SoC
CPU
- CPU 内部寄存器由算术逻辑单元 ALU 和 R0~R15 寄存器组成,从内存读取的值会先暂时保存在 R0 ~R15 中,经 ALU 计算后的结果也暂时保存,然后写入内存
- 对于 R13~R15 还有其他用途,R13 为栈指针 SP,R14 为 LR 用于保存返回地址,R15 为程序计数器 PC,表示当前指令地址
位、字节、字
- 位(bit):最基本单位,为 0 或 1
- 字节(Byte):数据存储的基本单位,1 字节 = 8 位
- 字(Word):数据处理和运算的单位,根据不同位机会有所不同
- 在 32 位机中:1 字 = 4 字节 = 32 位
- 在 64 位机中:1 字 = 8 字节 = 64 位
相关汇编指令
(1)读写内存:
(2)出入栈:
3.5.2. 堆栈
- 堆
(1)定义:一块空闲的内存,可以对其管理,需要的时候取出,用完的时候释放
(2)堆管理:实际的堆管理函数,首先基础的会分配一个头部 + 需要的内存,返回内存首地址,其中头部保存了需要的内存的大小,在释放时就会释放内存首地址 + 需要的内存的大小这一段的内存,通常用链表来管理堆(例如释放时两处不连续的内存)
- 栈
(1)定义:一块内存空间,CPU 的 SP 寄存器指向它,它可以用于函数调用、局部变量、多任务系统里保存现场
(2)函数调用在汇编中使用 BL 指令:将下一条指令地址保存至 LR 寄存器用于返回,并将调用的函数地址保存至 PC 寄存器用于跳转
(3)局部变量也会保存在栈里,当未加 volatile 关键字时,编译器会选择放在寄存器里再保存至栈里,速度更快,当加了 volatile 关键字或寄存器不够时,会直接保存在内存里而不通过寄存器
(4)RTOS 中需要频繁切换任务,而每个任务都有自己的函数调用、自己的局部变量等与其他任务无关联的内容,因此每个任务都会有单独的栈用于保存现场,切换出去前入栈保存现场,切换回来后出栈恢复现场,因此每个任务都有单独的栈互不影响
3.5.3. FreeRTOS 源码
- 目录结构

- 编程规范
(1)变量名简写:
- 内存管理
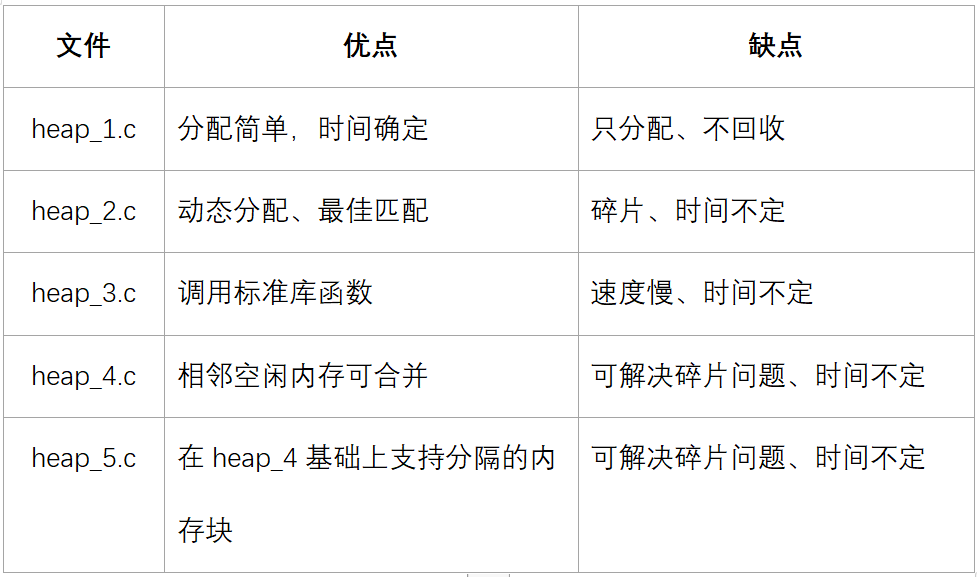
- 相关 API:
pvPortMalloc / vPortFreevoid* pvPortMalloc(size_t xWantedSize); // 单位为字void vPortFree(void * pv);- 作用:分配内存、释放内存
- 如果分配内存不成功,则返回值为 NULL
xPortGetFreeHeapSizesize_t xPortGetFreeHeapSize(void)- 当前还有多少空闲内存,这函数可以用来优化内存的使用情况;比如当所有内核对象都分配好后,执行此函数返回 2000,那么 configTOTAL_HEAP_SIZE 就可减小 2000;注意 heap_3 中无法使用
xPortGetMinimumEverFreeHeapSizesize_t xPortGetMinimumEverFreeHeapSize(void)- 返回:程序运行过程中,空闲内存容量的最小值
- 注意:只有 heap_4、heap_5 支持此函数
- 相关 API:
3.5.4. 任务管理
- 创建任务时估算栈的大小
(1)一个任务包括:函数、栈和 TCB(Task Control Block)、优先级
(2)因此任务分配分为动态分配和静态分配
(3)每个任务的栈包含:
(4)粗略的计算就是按照上面三个部分依次评估计算,算出 sum 字节后除以 4 得到 sum/4 字即栈大小
- 最终确定栈的大小
(1)获取当前任务剩余栈空间(单位:字)
(2)将分配的栈空间 - 最小剩余栈空间 = 实际使用的栈空间
(3)则最终确定栈大小 = 实际使用的栈空间 × (1.3~2)
(4)注意 printf 至少多出 25 字(100Bytes)栈开销,频繁调用/复杂格式化时甚至会多 100 字开销(400Bytes)
- 创建任务时给任务函数传入的参数
(1)观察创建任务函数原型:
(2)因此我们创建任务时传入的第一个参数的原型必须为:
(3)当为第一种时,参数可以利用结构体来传入多个参数:
- 任务状态
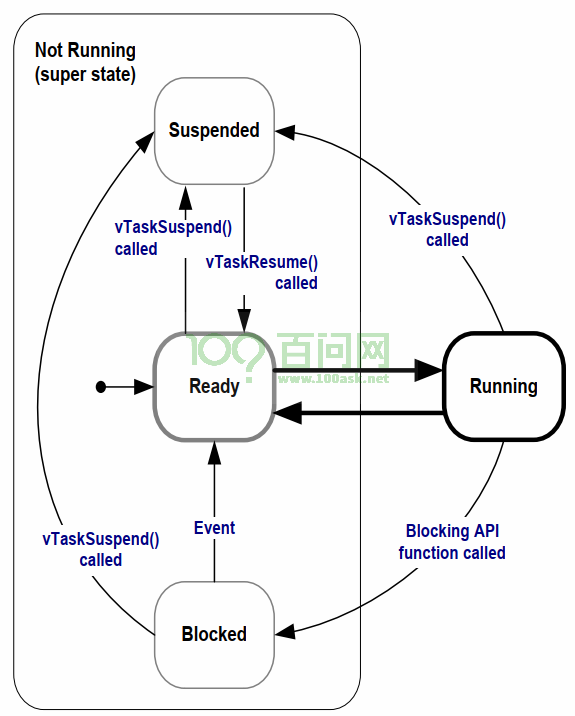
- 任务调度
(1)根据优先级定义就绪态数组:List_t pxReadyTasksLists[configMAX_PRIORITIES] = {0};
(2)数组每个成员是对应优先级的链表,同优先级的任务之间用链表连接管理
(3)创建任务时都会创建对应的 TCB 结构体,并用全局指针 pxCurrentTCB 连接到链表上;因此在调度器初始化创建任务时,按照代码顺序 pxCurrenTCB 依次连接,最后 pxCurrentTCB 会指向优先级最高的最后创建的任务对应的 TCB 结构体,注意 pxCurrentTCB 只会指向 Ready/Running 状态的任务
(4)当某个任务 Running 时创建了一个新的更高优先级的任务,那么就会立即跳转到更高优先级的任务(Ready 状态 转向 Running 状态,此时位于 pxReadyTaskLists 数组中);当任务中有 vTaskDelay 阻塞时,会从 Ready/Running 状态转向 Blocked 状态,同时从 pxReadyTaskLists 数组中转移到另一个 Delay 的数组,此时 pxCurrentTCB 就会根据 index(当前任务的上一个任务)重新按链表顺序去调度、指向新任务
(5)Reday/Running 状态的任务位于 pxReadyTasksLists 数组,Blocked 状态的任务位于 xDelayedTaskList1/2 数组,Suspend 状态的任务位于 xSuspendedTaskList 数组
(6)当宏 configUSE_PREEMPTION=1,即开启抢占式时,即使同优先级任务中有阻塞延时,也会每 1ms 按链表顺序依次调度执行,但低优先级任务则没有机会执行
- 空闲任务
(1)优先级最低,内置了清理代码,即负责释放被删除任务的内存
(2)当宏 configUSE_IDLE_HOOK=1 时,空闲任务的钩子函数启用,可自行添加需要执行的代码
(3)但注意钩子函数会在空闲时每 1ms 执行一次,因此需要添加标识符来规定如何执行
- 两个 Delay
(1)相对延时
(2)绝对延时
3.5.5. 同步与互斥与通信
- 为什么不能用全局变量实现同步
(1)通常同步互斥是绑定的,对于临界资源,如存在一个变量,AB 都想使用,则 A 使用时 B 必须等待;或者如 IIC 读取数据,A 和 B 都要使用 IIC1,则任务切换会导致 IIC 数据错乱;此时就需要互斥保护临界资源
(2)在裸机系统中通常使用全局变量作为标识符实现同步,但在 RTOS 系统中需使用其自带的信号量
(3)首先,因为对于同优先级的任务 A 和 B,当 B 处于 while(Flag == 0);等待阶段时,RTOS 调度仍然是 1ms 由 A 运行,再 1ms 由 B 运行频繁切换,这就导致 B 浪费了 CPU 资源,总共使用的时间里一半 A 使用,一半 B 等待,效率显然减半,因此不能使用全局变量来实现同步
(4)其次,存在一种可能,当 A 通过标识符判断可以使用临界资源并准备设置标识符前,刚好发生任务切换,B 发现标识符没设置,能够使用临界资源,则 B 开始使用,使用到一半时又发生了任务切换,此时虽然 B 设置了标识符,但 A 因为保护现场并恢复现场回到的地方是判断之后,则设置的标识符就无效了,A 继续使用临界资源,则此时便破坏了临界资源;这种可能概率很小但并不为零,因此全局变量有风险
(5)其实第二种情况在裸机下也可能存在,即低优先级中断被高优先级中断打断时,因此即使是裸机系统也要考虑临界资源,要对临界资源进行原子性操作
(6)原子性操作最简单粗暴方法就是开关中断,但此时就会出现第一种情况,尤其是在 RTOS 中更为明显
(7)以上的临界资源的情况,在通信时也会出现,通信数据也是一种临界资源
- FreeRTOS 中的方法
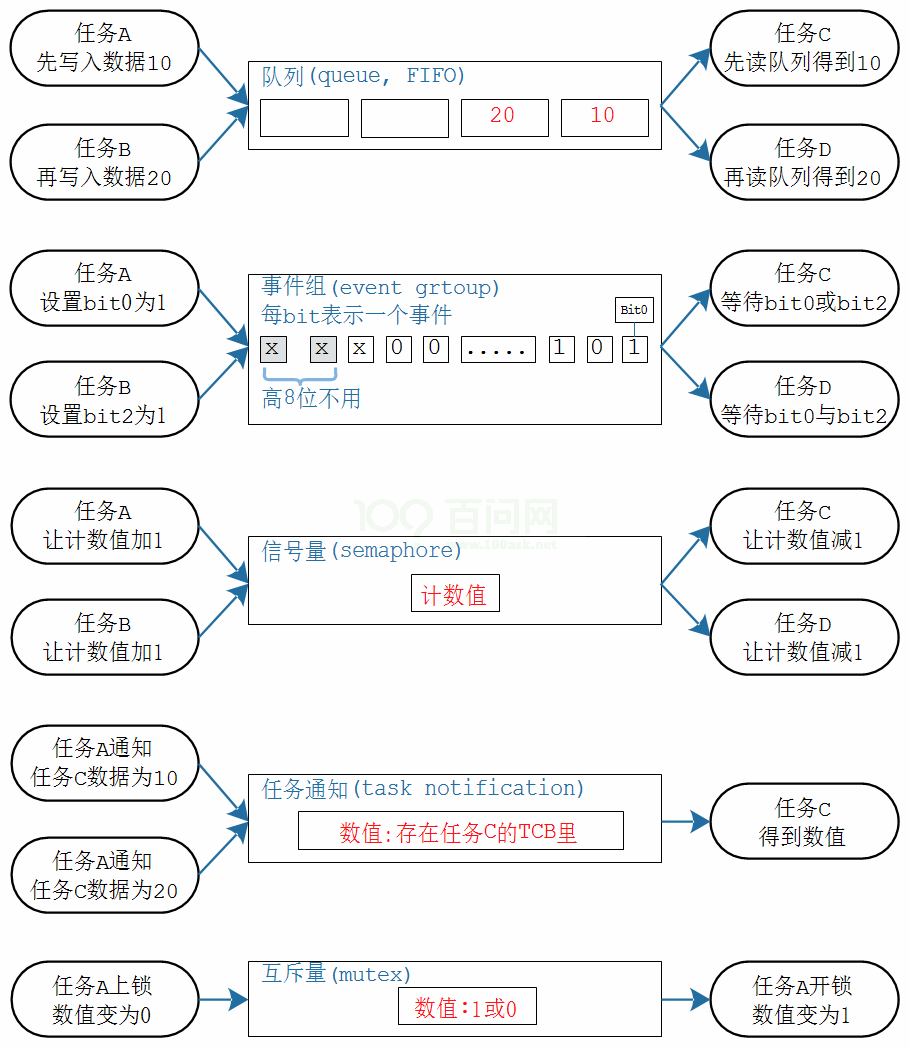
3.5.6. 数据传输方法:队列
- 前置:环形缓冲区
(1)队列是在环形缓冲区的基础上增加了互斥措施和阻塞-唤醒机制
(2)实现:
(3)注意环形缓冲区只有在两个任务之间读和写才不会有全局变量的缺陷,多个任务时需要使用队列
- 队列的本质
(1)队列是在环形缓冲区的基础上增加了互斥措施和阻塞-唤醒机制
(2)如果队列不传输数据,只调整数据个数,则被称为信号量
(3)如果限制数据个数为 1,则被称为互斥量
(4)队列的本质:
(5)任务 A 想读取队列但此时队列并无数据时可选择等待:则任务 A 从 Ready/Running 态转向 Blocked 态,并连接到 xTasksWaitingToReceive 和 xDelayedTaskList 两个链表上
(6)写队列时同理,链表为 xTasksWaitingToSend 和…,注意中断时需使用带 FromISR 后缀的函数
- 队列集
(1)队列集的本质也是队列,只不过里面存放的是“队列句柄”
(2)应用于多个硬件驱动需要读取时,硬件驱动触发中断并在中断里写队列,如果每个硬件都单独写个任务来进行读队列和数据处理,那就非常浪费内存,因此便有了队列集
(3)每个硬件驱动触发中断时在中断里写对应的队列,然后所有队列都放在队列集里,队列集存放所有队列的队列句柄,此时只需为队列集开一个任务,并在该任务里等待读队列,唤醒时读取队列集里的队列句柄,再根据队列句柄读对应的队列数据,然后处理数据并写入应用层的队列供队列层使用
(4)驱动层\xrightarrow[队列放入队列集]{写入队列}服务层\xrightarrow[数据写入队列]{处理数据}应用层
(5)注意创建队列集时,队列集深度 = 预期的最大并发通知数( ≤ 所有队列的深度总和)
(6)注意队列集里添加队列时,只能添加空队列,所以要先添加进队列集后再使用队列
3.5.7. 信号量与互斥量
- 信号量
(1)简单理解就是退化的队列,进入队列的数据只是用来计数;深度为 1 时为二进制信号量
(2)信号量相较于队列效率更高、更省内存;只有两个动作:"give"计数值加一、"take"计数值减一
(3)二进制信号量创建时从 0 开始;计数信号量创建时可设置深度、初始值
- 互斥量
(1)信号量的"take"和"give"动作任何任务都可以完成,无法实现互斥;互斥量是带互斥的二进制信号量
(2)互斥量的核心在于:谁"上锁"就只能由谁来"开锁",即谁"take"的就只能由谁来"give"
(3)在计算机中,互斥量通常应用于实现原子性操作和实现可重入函数
(4)原子性操作即本次操作在过程中不能被打断,必须一次性完成
(5)可重入函数即多个任务/中断同时调用它时函数的运行依旧是安全的,不会出现错误或混乱;通常一个函数只使用局部变量就必然是可重入函数,而使用全局变量的函数就必须依赖于互斥锁来实现可重入
(6)上述两种情况都存在临界资源:全局变量、使用全局变量的函数
(7)互斥量对临界资源的保护过程:
(8)优先级继承:
(9)死锁:
3.5.8. 事件组与任务通知
- 事件组
(1)多对一或多对多的情况,可以按下列代码理解:
(2)事件组高 8 位是给内核用的,其他位来表示事件
(3)信号量、互斥量是消耗性资源且只会唤醒一个任务,而事件组是广播性资源,满足要求的任务都会被唤醒并可选择保留事件组还是清除事件组对应的位
(4)事件组还具有同步功能,可在任务自己的事完成后设置事件组并等待对应位的事件也完成
- 任务通知
(1)任务通知效率最高,最节省内存,但不能发送数据给 ISR,因为是利用任务结构体定位目标任务
(2)原理:每个任务都有一个结构体(TCB),里面有两个成员(uint8_t 通知状态、uint32_t 通知值),直接通过任务句柄确定目标,直接修改任务结构体来实现通知
(3)通知状态有三种:
(4)有两组任务通知函数:一组简化版相当于轻量信号量(二进制/计数),另一组相当于轻量事件组
- 本文链接:https://kaede-rei.github.io/learning-path/electrical-control/3-5
- 版权声明:本博客所有文章除特别声明外,均默认采用 CC BY-NC-SA 许可协议。

